延續上一篇Lambda應用~
在Stream操作中加入peek主要用來監看資料內容,但須搭配一個結束操作,通常是collect
List.of("A", "B", "C", "D").stream().peek(System.out::println); // 無法印出任何東西
List.of("A", "B", "C", "D").stream().peek(System.out::print).collect(Collectors.toList()); // ABCD
將stream整理好的資料轉為新的集合或物件
// List 轉為 String
List.of("A", "B", "C", "D").stream().collect(Collectors.joining());
// List 轉為集合 toList, toSet, toMap, toCollection 等等
List.of("A", "B", "C", "D").stream().collect(Collectors.toList());
// List 根據指定的 Key 進行資料分組
List.of("A", "B", "C", "D", "D").stream().map(it -> Book.builder().bookId(list.indexOf(it)).name(it).build()).collect(Collectors.groupingBy(Book::getName)); // 轉為 Map<String, List<Book>> 集合型態 A{A=[Book(bookId=0, name=A)], B=[Book(bookId=1, name=B)], C=[Book(bookId=2, name=C)], D=[Book(bookId=3, name=D), Book(bookId=3, name=D)]}
在一開始將集合物件轉為stream時,還有另一個選擇就是parallelStream,可以將資料進行平行處理,根據電腦CPU最多可執行的Thread來決定上限。須注意parallelStream多執行緒在非Thread Safe物件誤用可能出現非預期錯誤。且執行速度在資料大於一定的程度才會較快,使用尚須小心。
// Output1可以看出使用parallelStream在4 core的電腦有8個Thread的都會用到
List.of("A", "B", "C", "D","A", "B", "C", "D","A", "B", "C", "D","A", "B", "C", "D").parallelStream().map(it -> Book.builder().bookId(list.indexOf(it)).name(it).build()).peek(it -> System.out.println(it + " " + Thread.currentThread().getName())).collect(Collectors.toList());
// Output2可以看出當資料量在100000時使用parallel處理反而比較慢,但資料量提升至10000000時,就變比較快了
LocalDateTime start = LocalDateTime.now();
List<Book> a = IntStream.range(1, 100000 + 1).parallel().boxed().map(it -> Book.builder().bookId(list.indexOf(it)).name(it.toString()).build()).collect(Collectors.toList());
System.out.println("parallel執行,資料量: " + a.size());
System.out.println(Duration.between(start, LocalDateTime.now()).toMillis());
LocalDateTime start1 = LocalDateTime.now();
List<Book> b = IntStream.range(1, 100000 + 1).boxed().map(it -> Book.builder().bookId(list.indexOf(it)).name(it.toString()).build()).collect(Collectors.toList());
System.out.println("循序執行,資料量: " + b.size());
System.out.println(Duration.between(start1, LocalDateTime.now()).toMillis());
// HashMap並非Thread Safe,造成非預期錯誤
Map<Integer, Integer> map = new HashMap<>();
Map<Integer, Integer> concurrentHashMap = new ConcurrentHashMap<>();
List<Integer> e = IntStream.range(1, 1000 + 1).boxed().collect(Collectors.toList());
System.out.println("List 資料量: " + e.size());
e.parallelStream().forEach(it -> map.put(it, it));
System.out.println("HashMap 資料量: " + map.size());
e.parallelStream().forEach(it -> concurrentHashMap.put(it, it));
System.out.println("ConcurrentHashMap 資料量: " + concurrentHashMap.size());
Output1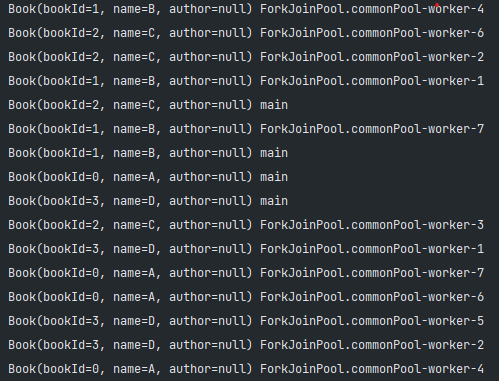
Output2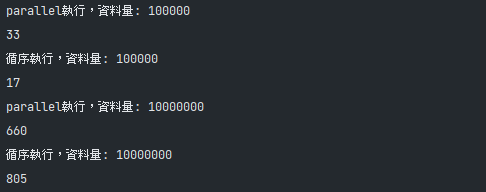
Ootput3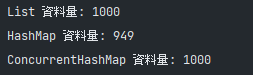
所以強烈建議大家可以多利用Java Lambda 的寫法讓程式變得更簡潔,邏輯也會更加清晰 


 iThome鐵人賽
iThome鐵人賽